
📄 The Motivation
Working with LLM-based RAG (Retrieval-Augmented Generation) systems like Microsoft’s GraphRAG, you quickly learn one thing: token usage = money.
Despite GraphRAG’s robust indexing flow, it lacked one important visibility tool: the ability to estimate LLM cost before committing to indexing large datasets.
So I built it.
⚡️ The Problem
Indexing isn’t free. The process involves:
- Embedding tokens using models like e.g.
text-embedding-3-small - Chat completion calls for summarization
Yet, GraphRAG gave no clue about how many tokens would be consumed before launching the job.
For developers with limited OpenAI credits, or for teams working on large corpora, this is a silent risk.
⚙️ What I Built
I added a CLI-based feature that lets you run:
graphrag index \
--root ./ragtest \
--estimate-cost \
--average-output-tokens-per-chunk 500And get a full preview like:
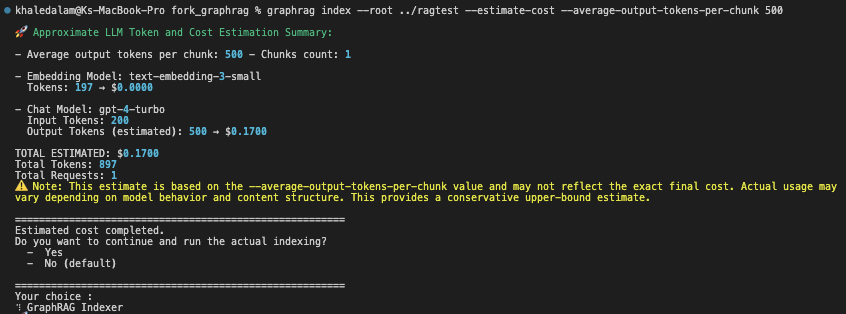
🚀 Approximate LLM Token and Cost Estimation Summary:
- Average output tokens per chunk: 500 - Chunks count: 1
- Embedding Model: text-embedding-3-small
Tokens: 197 → $0.0000
- Chat Model: gpt-4-turbo
Input Tokens: 200
Output Tokens (estimated): 500 → $0.1700
TOTAL ESTIMATED: $0.1700
Total Tokens: 897
Total Requests: 1
⚠️ Note: This estimate is based on the --average-output-tokens-per-chunk value and may not reflect the exact final cost. Actual usage may
vary depending on model behavior and content structure. This provides a conservative upper-bound estimate.
=======================================================
Estimated cost completed.
Do you want to continue and run the actual indexing?
- Yes
- No (default)
=======================================================
Your choice :
🧪 Under the Hood
- Uses
TokenTextSplitterto simulate chunking logic - Dynamically loads pricing from my hosted JSON:
openapi-pricing - Handles pricing fallback if model not found (e.g.
gpt-4o-preview→gpt-4-turbo) - Estimates output token cost using a configurable
--average-output-tokens-per-chunk
🚀 Fun Fact About tiktoken
While TokenTextSplitter is sufficient for simulation, tiktoken is the source of truth when reconciling estimates with OpenAI’s billing dashboard.

During a few intense days of development on this feature, I was also benchmarking tokenizers in Rust and C++ against OpenAI’s tiktoken and Hugging Face’s tokenizer libraries. As a result, I forgot to uninstall my local debug build of tiktoken

Lesson learned: always clean up your dev tools when switching contexts!
🪧 Challenges I Solved
- ❌ Avoiding
RuntimeError: no current event loopby usingnest_asyncio - ⚠️ Matching chunking logic to GraphRAG’s actual pipeline
- 💳 Normalizing pricing data (stored in cents, converted to USD)
- ❗ Guarding against poor input content (e.g., non-strings, blank rows)
🔎 Accuracy vs. Reality
The estimate is conservative. It includes both:
- Actual embedding token count
- Estimated output tokens based on your config (default 500 per chunk)
This matches OpenAI dashboard reports fairly closely, but can overestimate slightly, which is intentional.
🔗 Try It Yourself
Pull Request: #1917
🙌 Why It Matters
Giving devs token-level cost insight before running expensive jobs improves:
- Transparency
- Predictability
- Financial safety
It’s also one step closer to production-grade RAG systems.
💬 Let’s Connect
Learn how I added a cost estimation feature to Microsoft GraphRAG’s indexing pipeline, enabling developers to preview LLM token usage and projected OpenAI API costs before processing large datasets.